Load Testing With Locust
We spend some time each dev cycle working to improve the performance of specific pages on our app. There are some low hanging fruit — optimizing database queries, etc. But there are other things we have been trying to, and we wanted to see what impact those things were having, if any, with data. Enter Locust (oh hey, it’s the docs. It basically allows you to hit your application in a controlled manner, much harder than it might otherwise be hit, to show you fail rates, requests per second, etc. At that point, you can establish a baseline, make changes, and see what happens!
Writing a locustfile
There are more examples in the docs, but here’s what mine looked like:
from locust import HttpLocust, TaskSet, task
LOGIN_URL = “/login/?next=/”
class LoginAndViewCourse(TaskSet):
def on_start(self):
self.login()
def login(l):
response = l.client.get(LOGIN_URL, name=”LOGIN_URL”)
csrftoken = response.cookies[‘csrftoken’]
l.client.post(LOGIN_URL, {“login”:”example@example.com”, “password”:”locust”}, headers={“X-CSRFToken”: csrftoken}, name=”LOGIN_URL”)
@task(1)
def lesson(l):
l.client.get(“/path/to/course”)
class MyLocust(HttpLocust):
task_set = LoginAndViewCourse
min_wait = 0
max_wait = 0
What this does is pretty straightforward: it logs a user in, and then it hits the path to the course. In my case, the page I’ve specified I want to visit requires some existing database relationships (the user already exists, etc.). While I could certainly use my on_start function to create these via the interface, it was easier for me to make sure they already existed before running the tests. But be aware that things like that may cause different results than you were expecting. I found it useful to watch my logs as the test was running to make sure I was getting 200 responses, not 302s that would have indicated incorrect setup.
The min_wait and max_wait are optional arguments (they default to 1000), that specify how long to wait between requests. Mine are set to not wait at all — just hit the servers as hard as it can.
Since my use case is working to optimize a single page in isolation, I’m only hitting that single path. If you wanted to look at data more generally or replicate the kind of traffic that your application actually gets, you can build as many tasks as you want, and they will be run in random succession. The number after the @task decorator gives them a weight, which allows you to manage which tasks are hit more often than others (the higher the number, the more frequently that task will be hit)
Running a locustfile
Since I’m working in Django anyway, and my machine is set up for Python, I created a locust virtualenv that has everything I need. If you’re not already set up for Python, you may need to do some installing. You can then run your locustfile by running locust --host=http://mydomain/ from within my locust virtualenv.
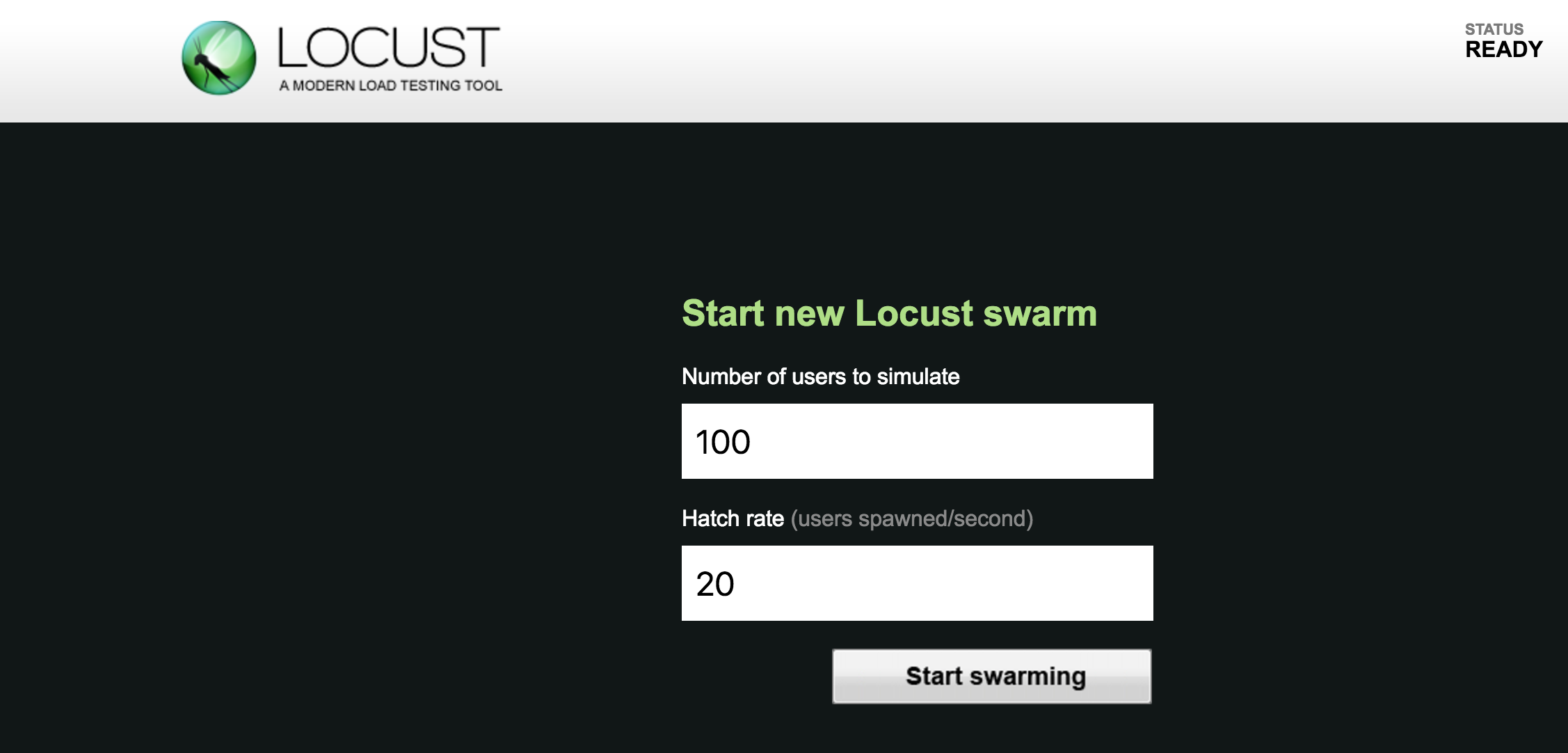
You can then use the UI at *:8089 (which it will remind you of when you start) to tell it how many users to test and at what rate to spawn them:
After that, you just watch the results roll in:
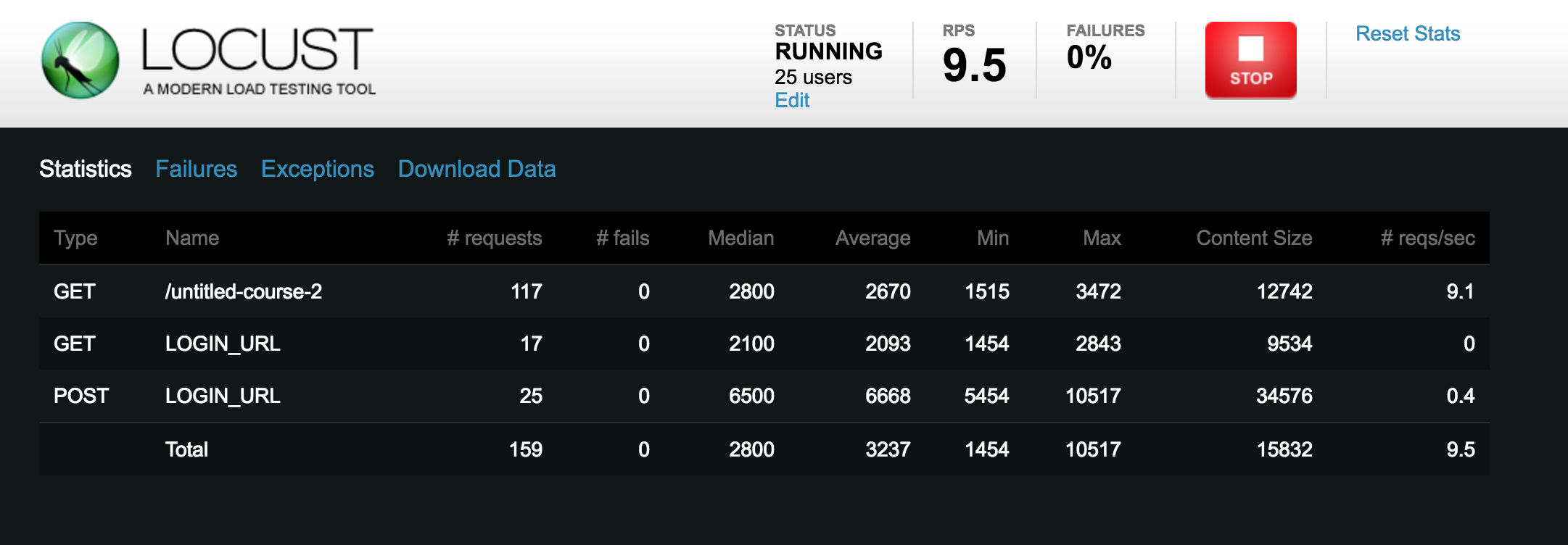
To note: if you change your locustfile, you’ll need to stop and restart locust from your command line for the changes to take effect.
Replicating Production
I’m obviously not doing my load testing on production. I’m trying to bring it down, after all (It should go without saying that you shouldn’t be an asshole. You wouldn’t do it to your site, so don’t do it to anyone else’s either). But to get accurate data, I wanted it to resemble production however possible. A couple of things that meant in adjusting my staging environment:
- Turn off sticky sessions, if you have them on. If your load on production is split between multiple servers, if your locust test replicates only a single logged in user, as mine does, all of your requests may not be routed the way they would in production.
- Background tasks: my local setup runs things in the foreground that are run as background tasks on production, which obviously hampers local performance — this is usually fine since I’m the only one using it. But it does mean that it made more sense for me to run this test against staging, or at the very least, connect my local setup to a queue.
Overall: data is cool. Some things I expected to make a big difference made none at all, and looking at the logs and database calls after a test like this helped me hone in on where my bottlenecks were to find what might be impactful.