Iterating on Database Architecture
I am building an API using data from the Washington State Department of Education. As with most DOEs, they provide a huge number of excel spreadsheets containing all kinds of data, which I’m normalizing before putting into my database. I’ve been working on this for about a week now, and already have three iterations of my database architecture, but it’s at a point now where I feel comfortable that I will be able to grow the scope of the application and add data to it without needing to redesign it each time — which is the point, of course!
First Iteration
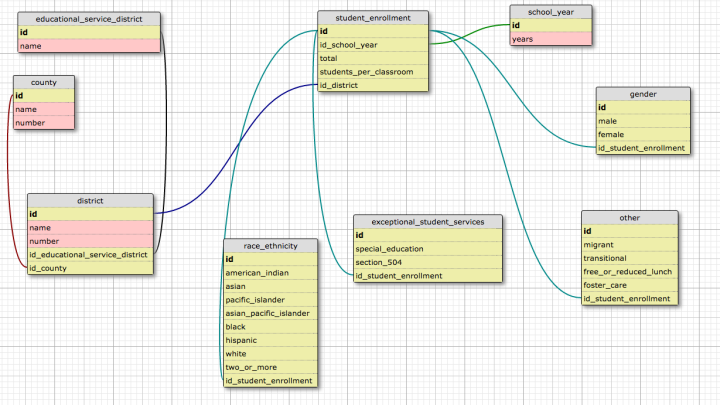
The first dataset I brought in was demographic data. This design worked well with that limited subset of available data, but was not scalable. It used aStudentEnrollment object as the central organizing factor, and had relationships with different demographic factors, which was not scalable to different data types.
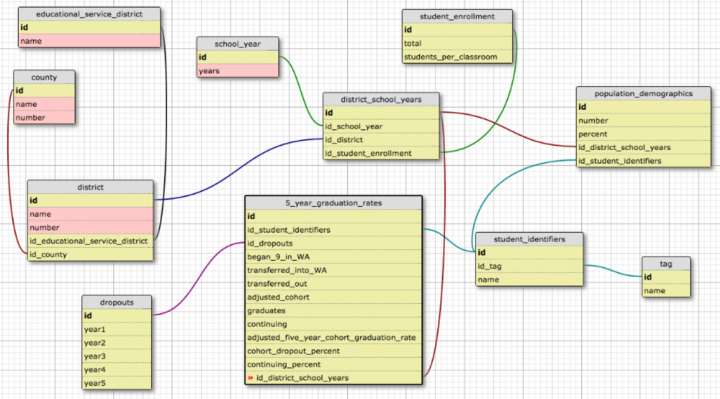
Second Iteration
The second dataset I brought in was graduation data. This data is broken down by the demographic groups represented in the first iteration, which shifts the organizing principal of the data. It uses a district and a school year as the central element, and this combination provides relationships to all of the other elements. In this example, a Tag is something like ‘race and ethnicity’ or ‘exceptional student services’ and a StudentIdentifier is something like ‘special education’ (would belong to the ‘exceptional student services’ tag ) or ‘two or more races’ (would belong to the ‘race and ethnicity’ tag). This allows both graduation and demographic data to be tied to a StudentIdentifier without redundancy.
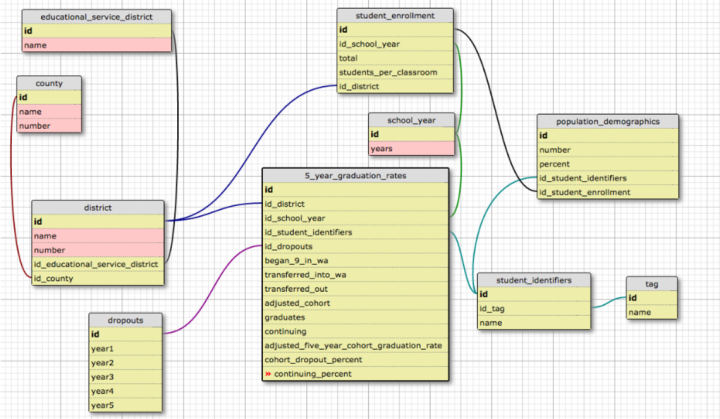
Third (Final?) Iteration