Character Encoding Inernet
My partner ran into a character encoding issue at work recently that we were talking about over dinner (you all talk about things like character encoding at dinner too, right?), and I realized I knew less about it than I wanted to. And as usual, one of my favorite ways to learn something new is to write a blog post about it, so here we are!
High level, we know that all data transferred over the internet in packets made up of bytes — so when it comes to character encoding, the question becomes: how do all the characters that our users enter into forms, or that we pull out of or send to the database, or receive from external API calls, become bytes that can be passed over the network?
We need a way to turn all of these numbers and letters and symbols into bits — this is called encoding.
Character Sets
A character set is not technically encoding, but it is a prerequisite to it. It represents the set of characters that can be encoded, and usually assigns them a value that is converted into bytes during the encoding step. ASCII and unicode are examples of this.
ASCII
ASCII was one of the earlier character sets. Here’s a table that shows how characters are included:
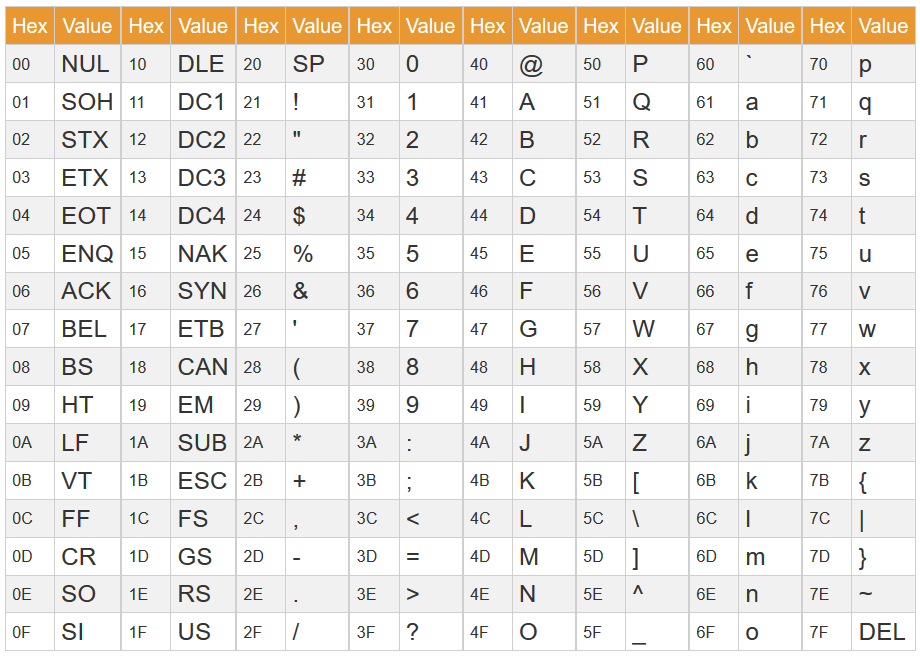
The problem with this is pretty immediately obvious, isn’t it? What if you want to use a non-latin alphabet? What if you want to use a special character (for example: ©) You can’t. So while ASCII is still used (for example, all URLs must use only ASCII characters), it’s really not very useful for transferring data across networks.
Unicode
Enter unicode. Unicode was developed as a global standard to encode all characters in all languages (not to mention emoji and other special characters). Unicode actually does use the same character mappings as ASCII for the characters that are included in it, it just includes a lot more (a lot — there are 1,114,112 possible unicode characters. You can see all of them here, if you’re curious!).
Encoding
Encoding is how we actually convert these mapped character values into bits that can be transferred over networks.
UTF-8 (+)
UTF-8, UTF-16, and UTF-32 are all different character encodings that work with unicode.
Because there are more than a million characters supported by unicode, we’d need a minimum of three bytes to represent all of them. But if we used three bytes for every character, we’d use a lot of unnecessary space, especially if we’re primarily working with a latin alphabet (not to mention no one wants to work with three bytes, which is why UTF-16 and UTF-32 are options, but UTF-24 is not — if that’s a rabbit hole you want to go down, you can read about the pros and cons of UTF-24 that were presented when it was proposed in 2007 here).
The 8, 16, and 32 respectively represent the minimum number of bits that will be used to represent a given character. The table below gives an example of what this might look like:

Base64
Base64 encoding takes us a little beyond encoding what we traditionally think of as strings or characters — it specifically allows us to encode binary data (think images or videos) and represent it as ASCII strings.
The algorithm for doing this encoding is a little more complicated than I want to get into here, but there are plenty of resources that go into depth on that. One telltale sign that you’re looking at a base64 encoded string is that it ends in = or == — these are used as padding characters to make sure the final byte in the encoded string is complete (a byte has 8 bits, so if the original string doesn’t have the right number of bits, it needs padding!)
Base64 is also often used to keep things out of plaintext, but it’s not encryption — it’s easily decode-able by anyone, without any signature or secret.
The content-length of base64 encoded data is usually about 33% longer than the original un-encoded data, so if you’re dealing with strings that have a max length limit, that will need to be taken into account.
Parting Notes — Practical application
Now that we know how and why characters are encoded, let’s look at a couple specific use-cases:
URLs can only contain ASCII characters, so if they contain any non-ASCII characters, they need to be URL-encoded. For example, a space symbol will become %20 with URL-encoding. Most programming languages have built-in URL encoding functions.
In order for a browser to render HTML, it needs to know which character encoding was used to produce it, so it knows which lookup table to use to transfer the bytes back into a human-readable format. That’s why the head of an HTML page contains something like this:
<meta charset= "utf-8"/>
However — if you send a different value through the HTTP headers (e.g. Content-Type: text/html; charset=utf-16), those will be given precedence over what’s found in the HTML header. It’s worth noting though that the HTML spec strongly discourages using anything other than UTF-8.